2025.04.28
ChatGPTファインチューニングとは?仕組みややり方・コストなどを1から徹底解説

ChatGPTを業務に活用する中で、「プロンプトの工夫だけでは、回答に限界を感じる」と感じている方も多いのではないでしょうか。より業務や自社の目的に沿った回答を得ることができれば、生成AIの効果を最大限に活用でき、自社の生産性はさらに向上します。 このようなニーズに応える手段として注目されているのが、「ファインチューニング」です。既存のChatGPTモデルに対し、企業独自のデータを用いて再学習を行うことで、自社の業務に特化したAIを構築できます。 とはいえ、導入のハードルが高そう、具体的な費用感が分からない、本当に成果が出るのかなどの不安を抱えている方も多いと思います。 本記事では、初心者でも理解しやすいように、ChatGPTのファインチューニングの仕組み・やり方・費用・成功事例までをまとめてご紹介します。
目次
ChatGPTのファインチューニングとは?
ChatGPTのファインチューニングとは、既存のChatGPTモデルに、自社の業務や目的に特化した追加学習を行うことを意味します。これにより、特定のドメイン知識や文体、応答傾向をAIに覚えさせ、より自社の業務に特化した回答を得ることができます。
プロンプトエンジニアリングとの違い
プロンプトエンジニアリングは、AIからの回答をより効果的なものにするためにAIに与える指示(プロンプト)を工夫することを指します。一方ファインチューニングでは、モデルそのものを再学習させるため、プロンプトエンジニアリングだけでは実現しづらい”高度な応答”ができるようになります。 たとえば、社内の用語やサービス特有の文脈を含むQAを正確に行いたい場合には、ファインチューニングを行うと良いでしょう。
なぜファインチューニングが注目されているのか
近年、企業では「汎用AI」から「業務特化AI」への移行が加速しています。社内ドキュメントや業務の詳細、FAQなどをAIに学習させることで、顧客対応や業務自動化における質の向上と効率化の両方を実現することができます。 この流れの中で、ファインチューニングはコストパフォーマンスが高い方法として、現場の注目を集めているのです。 ファインチューニングの必要性について、以下の記事も合わせて参考にしてください。
ファインチューニングのメリットとデメリット
ファインチューニングには数多くのメリットがありますが、同時にデメリットも存在します。ここでは、その両面を整理してご紹介します。
メリット
 ファインチューニングは、汎用モデルでは対応しきれなかった自社特有の課題にも柔軟に対応でき、実務レベルでの精度と効率を引き上げてくれるとても画期的なAIの活用法です。ここでは、その具体的なメリットを解説します。
ファインチューニングは、汎用モデルでは対応しきれなかった自社特有の課題にも柔軟に対応でき、実務レベルでの精度と効率を引き上げてくれるとても画期的なAIの活用法です。ここでは、その具体的なメリットを解説します。
自社の業務に特化したAIを作れる
ファインチューニングによって、社内のFAQ、業務マニュアル、対応ログなどを学習させることで、特定業種・職種に特化したAIをつくることができます。汎用モデルでは理解できなかった業界用語や社内ルールにも的確に対応でき、まるで専任スタッフのような精度の高い対応が可能となります。
プロンプトの簡略化が可能
ファインチューニングされたモデルは、文脈や背景をすでに理解しているため、複雑なプロンプトを用意しなくてもシンプルな指示で得たい回答を得ることができます。例えば、「商品説明を書いて」といった抽象的な指示でも、学習済みのルールに従って質の高い出力が得られるので、AIの知識が豊富でなくてもAIを使いこなせるようになります。
長文や複雑なデータに強くなる
複雑な条件がある場合や例外の多い業務対応でも、ファインチューニングされたモデルであれば一貫した出力が可能になります。たとえば、製造業の工程管理や法務対応のような複数の要件を踏まえる場面でも、整合性のある判断や回答を返せるため、AIを業務に使える幅が広くなります。
応答精度の向上
モデルが企業固有の表現や回答パターンを学習しているため、類似質問にも高い再現性をもった回答が可能になります。そのため、チャットボットやヘルプデスクといった顧客サポートと相性が良く、CS(顧客満足度)の向上にも繋がります。
APIコストの削減
ファインチューニングにより、プロンプトが短くても高精度な応答が可能になるため、従来よりも少ないトークン数でやり取りが完結し、API利用料金(従量課金制)の削減につながります。特に高頻度でAPIを呼び出すチャットボットや自動化システムにおいては、月単位での大幅なコスト削減が期待できます。
デメリット
 ファインチューニングには、多くのメリットがある一方でデメリットも存在します。導入の前に以下のデメリットがあることをしっかりと把握しておきましょう。
ファインチューニングには、多くのメリットがある一方でデメリットも存在します。導入の前に以下のデメリットがあることをしっかりと把握しておきましょう。
高度なデータ準備が必要
ファインチューニングの精度は、与えるデータの質に大きく左右されます。社内ドキュメントをそのまま使うとChatGPTの誤学習の原因となるため、不要な情報の削除、フォーマット統一、文体の調整などといった前処理作業が必要になります。初期段階では自社だけで行うのはかなり高度で、専門的な知識と十分なリソースが必要になります。弊社のAIサポートでは、ファインチューニングのサポートも行っております。ぜひお気軽にご相談ください。
エンジニアリングスキルが求められる
モデルの学習やAPI設定には、Pythonやコマンドラインツールの操作が必要です。また、データの構文エラーや学習ログの管理、トラブル対応にも一定の知識が必要となるため、実装の際は、エンジニアをチームに入れた方が良いでしょう。
【e仕事エンジニア】エンジニア向けの求人メディア|日研トータルソーシング
費用がやや高め
ファインチューニングはトークン単位の従量課金制であるため、データ量が多かったり学習回数が多いとコストがかさみます。加えて、実運用中も応答ごとに推論コストが発生するため、プロジェクト単位ではなく「運用全体の費用設計」が重要になります。実装する際には、費用対効果のシミュレーションを行うことが大切です。
継続的な更新が必要
モデルは学習時点の情報に基づいて動作するため、社内ルールや商品仕様、法改正などの変更には対応できません。そのため、定期的なデータ更新と再学習を行う必要があります。放置すれば間違った回答を行ってしまうため、顧客サポートの場面では、クレームにつながってしまうケースもあります。
誤学習・偏った回答のリスクがある
不適切なデータや偏った見方を含んだ内容で学習を行うと、AIはそれを正しい情報として処理してしまいます。特定部署の表現や一部の事例に偏った情報を学習させると、全社対応のAIとしては不適切な応答を返す可能性があり、企業ブランドや業務品質への悪影響につながる恐れがあります。
ファインチューニングの具体的な手順
このセクションでは、ファインチューニングの具体的な手順について説明します。
必要な準備(APIキー、環境構築など)
まず、OpenAIのアカウントを取得し、管理画面からAPIキーを発行します。続いて、学習用スクリプトやCLI(コマンドラインインターフェース)を実行するための開発環境を整えます。Pythonが使えるローカル環境やGoogle Colabなどを活用するのが一般的です。
APIキーの取得の仕方
OpenAIのプラットフォームにアクセスし、左下のAPIキーを選択します。  次に、緑色の「新しい秘密鍵を作成する」のボタンを押します。
次に、緑色の「新しい秘密鍵を作成する」のボタンを押します。  最後に名前とプロジェクトを記入すれば、APIキーを簡単に取得できます。取得したAPIキーはコピーで入手できます。
最後に名前とプロジェクトを記入すれば、APIキーを簡単に取得できます。取得したAPIキーはコピーで入手できます。 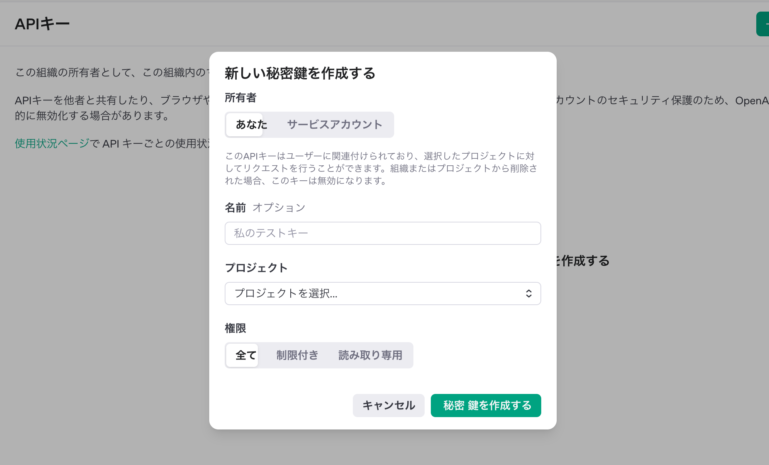
- 必要なツール・ライブラリ例
- Python 3.8 以上
- openai ライブラリ(pip install openai)
- JSONL形式の学習データ(後述)
- OpenAI CLI(npm または brew でインストール可)
データセットの構成と作成のポイント
ファインチューニングには、AIに学んでほしい会話例(質問と答え)を記載したファイルが必要です。このファイルは JSONL形式 という形式にする必要があります。1行ごとに1つの会話を記述します。以下がその例です。
 これを数百〜数千行分用意します。内容は、よくある質問、問い合わせ、社内用語など、目的に応じた内容を含めてください。
これを数百〜数千行分用意します。内容は、よくある質問、問い合わせ、社内用語など、目的に応じた内容を含めてください。
【作成時のポイント】
- 約数百〜数千件を用意すると安定した学習効果が得られる
- ユーザーとアシスタントの対話構造を厳密に記述
- 同じテーマの多様なパターンを含めることで再現性が高まる
- フォーマットエラーを防ぐため、事前に構文チェックを行う
学習~結果確認までの流れ
以下の手順でファインチューニングを進めます。
1.ファイルのアップロード

2.ファインチューニングの実行

3.学習の進捗確認(ログのモニタリング)

4.完了後のモデル確認とテスト
新しいファインチューニング済みモデルIDが発行されるため、それを使ってAPI経由で出力のテストを行います。 
5.本番運用
完成したモデルIDを活用して、チャットボットや社内システムなどに統合したら完成です。
実践事例:ChatGPTファインチューニングの成功例3選

医療分野で活用 |患者に説明する時間を約30%削減
 出典:大阪国際がんセンター
出典:大阪国際がんセンター
医療分野でもファインチューニングを活用し、成功した事例があります。大阪国際がんセンターでは、乳がん患者向けに対話型説明AIを導入しました。患者の質問に正確に回答してくれ、今までかかっていた患者に対する説明時間を約30%短縮しました。また、退院時の文章を自動作成するシステムは、今まで医師が掛かっていた文書作成時間を約67%削減し、全国の23件の病院で導入が進められています。
参照:生成AIのファインチューニング:産業応用の最前線 | 株式会社ProofX
製造業で活用 | 異常検知や予知保全で大幅な効率化
 出典:富士電機
出典:富士電機
製造業では、異常検知や予知保全においてファインチューニングが活用されています。大手電気メーカーの富士電機では、LSTMネットワークと時系列データ解析を組み合わせ、故障予測精度92%を達成しました。また、これにより、メンテナンスコストを30%も削減できました。
参照:生成AIのファインチューニング:産業応用の最前線 | 株式会社ProofX
小売業 | AIによる需要予測で廃棄ロスを約30%削減
日本の大手スーパーマーケットのライフでは、全店舗の生鮮部門発注に AI 需要予測 による発注自動化サービス「AI-Order Foresight」を導入し、廃棄ロスを約30%ほど、そして発注作業時間を50%以上削減しています。元々は、日配品に対して導入されていたものですが、生鮮部門の発注にも適用されるなど、その幅を拡大しつつあります。また、アメリカの大手スーパーマーケットのウォルマートでも、需要予測モデルを店舗別にファインチューニングし、在庫過剰を40%も削減することに成功した事例があります。
参照:生成AIのファインチューニング:産業応用の最前線 | 株式会社ProofX
ファインチューニングのコストと料金体系
本セクションでは、ファインチューニングのコストについて解説していきます。かかるコストをしっかりと理解し、費用対効果を考えましょう。
gpt-3.5-turbo等モデル別の価格比較
OpenAIの提供する主要モデルの価格は以下の通りです。(2024年時点) 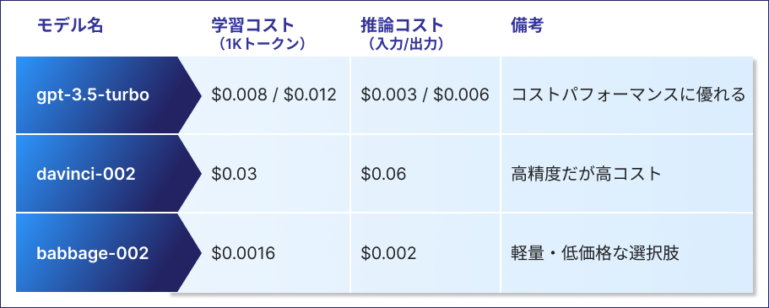
学習・推論におけるトークンコストの仕組み
ファインチューニングでは、データの「トークン数」に応じて料金が発生します。1Kトークン=約750単語相当です。たとえば10万トークンを10回学習した場合、学習コストだけで約$8〜10かかります。推論時も入力と出力の合計トークンに応じて従量課金されます。
実際にかかる開発費・保守費の例
ファインチューニングの実施に伴う費用は、APIの利用料金に加えて開発・運用体制によって変動します。たとえば、gpt-3.5-turboモデルで10万トークンの学習を10エポック実施した場合、学習部分のAPIコストは10ドル前後で済みます。しかし、実際のプロジェクトでは以下のようなコストが発生します。
- 開発の設計・実装にかかる社内人件費または外注費(PoC実施で20万~100万円が一般的)
- 学習や検証時の再学習に伴う追加API利用料(1回あたり10~30ドル)
- 運用フェーズでのAPI呼び出しコスト(月数千~数万リクエストで50〜300ドル程度)
- 年1〜2回のモデル更新費用(都度10〜100ドル程度)
こうした費用を踏まえても、人的リソースの削減効果や応答精度向上のインパクトを考えれば、中長期的な投資効果は十分に見込めます。
費用対効果を高めるための工夫
ファインチューニングの費用対効果を高めるためには、事前の戦略設計が欠かせません。特に、導入初期から「すべてを自動化しよう」とせず、よくある定型業務やFAQ対応など、成果が見えやすい領域から導入していくことが重要です。 加えて、コスト削減と運用効率を両立させるためには以下の工夫が有効です。
- 高精度だが高額なモデルより、gpt-3.5-turboなどのコスパに優れたモデルを選ぶ
- 学習データは最大量を目指さず、代表的なケースを厳選して品質を担保する
- トークン節約のために、プロンプトや応答文を簡潔に設計する
- モデル更新はフル再学習ではなく、差分更新方式を活用して効率化する
このように設計から運用までを戦略的に実施することで、成果を最大化できます。
導入前に知っておくべき注意点と失敗しやすいポイント
 導入前に注意点や失敗しやすいポイントを抑えておくだけで成功の確率がかなり上がります。以下のポイントをしっかりと押さえておきましょう。
導入前に注意点や失敗しやすいポイントを抑えておくだけで成功の確率がかなり上がります。以下のポイントをしっかりと押さえておきましょう。
失敗しやすいポイント
ファインチューニングはとても効果的なAIの活用法である一方、準備や設計を誤ると十分な効果を発揮できません。ここでは、初心者が特に注意すべき代表的な失敗例を整理します。
データ量不足
ファインチューニングの効果は、投入する学習データの「質」と「量」に大きく依存します。最低でも1,000件以上の対話例が望ましく、業務で頻出する問い合わせや会話パターンはできる限り網羅すべきです。少数の例だけでは、モデルが知識を十分に学習できず、逆に回答精度が低下するケースもあります。まずはよく使われるQ&Aを抽出し、それらを優先的に整備するのがおすすめです。
フォーマットミス
ファインチューニング用のデータは、JSONL形式(1行1JSON)で正確に作成する必要があります。カンマの入れ忘れ、クォーテーションの不統一、エスケープ文字の誤りなど、細かいフォーマットエラーが1行でもあると、学習全体が中断されることがあります。特に、Excelなどから手動でコピー&ペーストしたデータはエラーが起きやすいため、CLIでの事前検証を必ず実施しましょう。
偏った情報の出力
学習データが一部の業務部門や文体に偏っていると、ファインチューニング後のAIはその偏りをそのまま再現してしまいます。例えば、特定部署の用語や表現が強調されたデータだけで学習すると、他部署の利用者にとっては使いづらいモデルになります。部署やユースケースごとにバランスの取れたデータセットを作成し、多様な視点を網羅することが重要です。
チーム内での運用体制の整備
ファインチューニングは技術的な実装だけでなく、継続的な運用設計が成功の秘訣です。具体的には以下のような体制整備が必要です。
- データ担当
社内文書や対応ログを収集し、整理・整形する役割。 - 実装担当
OpenAI CLIやAPI操作を通じてファインチューニング処理を行うエンジニア。 - 評価・テスト担当
モデルの応答精度を定期的に確認し、再学習の必要性を判断する役割。 - 業務代表者
業務フローに合っているかを最終的にチェック。
このような分担でレビューサイクルを構築することで、運用後も継続的に品質を保つことができます。しかし、実際に誰をどこに配置するのか悩まれる担当者も少なくないでしょう。malnaのAI導入サポートでは、AIの技術的な支援だけでなく、このような体制の整備まで一から丁寧に行います。興味のある方は一度お問い合わせください。
セキュリティとデータ管理の注意点
ファインチューニングに使用するデータには、顧客情報、契約内容、機密事項などが含まれる可能性があります。誤って個人情報を含んだままアップロードしてしまうと、情報漏洩や社内規定違反のリスクを伴います。 安全な運用のために、以下の点に留意してください。
- 個人情報・機密情報の削除またはマスキング
氏名・住所・電話番号などは除外するか、置き換え表記に変換して学習データに含める。 - ファイルアクセス管理
学習データの編集・閲覧権限は最小限に限定する。 - 通信の暗号化とログの監査
API経由の通信はHTTPSを利用し、社内でもログの保存・監査体制を整備する。 - 利用規約・契約の確認
OpenAIのデータ利用ポリシーやAPIの利用規約を事前に確認し、自社のコンプライアンスに適合しているか確認する。
特に個人情報保護法や業界ごとの法令が適用される場合は、法務部門とも連携した導入が求められます。
まとめ
ChatGPTのファインチューニングは、企業の業務に特化した“自社専用AI”をつくるとても有効な手段です。FAQ対応の自動化、マニュアル業務の効率化、顧客対応の精度向上など、さまざまな領域で活用のメリットがあります。 しかしその一方で、誤った方法で導入を進めると、フォーマットエラーや学習データの偏り、セキュリティ面の不備といったデメリットももたらします。特に、誤った情報の学習や情報漏洩が発生した場合、顧客からの信頼を大きく失う恐れもあるため、慎重な設計と運用が求められます。 ChatGPTのファインチューニングは、貴社の業務を飛躍的に効率化する可能性を秘めていますが、「導入のハードルが高そう」「失敗なく進めたい」と感じる方もいらっしゃるかもしれません。 弊社では、ChatGPTをはじめとする生成AIの導入支援から社内運用体制の構築まで、一貫したサポートを提供しています。大手企業への導入経験もあるコンサルタントが、事前ヒアリングから運用設計まで丁寧に伴走いたします。 貴社がファインチューニングの効果を最大限に活用できるよう、着実な成果を積み上げるお手伝いをいたします。まずはお気軽にご相談ください。
無料相談はこちら執筆者情報
![]()
- writer malnaブログ編集部 webマーケター / データアナリスト
- Facebook・InstagramをはじめとするSNS広告からSEO対策など、マーケティングに関する様々な情報を発信しています。







関連記事タグをクリックでカテゴリページを開きます
-
2026.06.03
Slackでタスク管理を自動化した話 ― Claude Codeで社内Botを作るまで
-
2026.04.16
Claude Codeで広告分析と施策提案を自動化する方法【実務者向け】
-
2026.03.23
Claude CodeでSEO分析基盤をゼロから構築する全手順【実務者向け】
-
2025.04.05
使えないと非効率的!社会人なら知っておきたい ChatGPTを使ったExcel・スプレッドシートの自動化
-
カスタムGPT(GPTs)とは?活用事例・設定方法を解説!






- malnaのマーケティングについて
-
弊社ではメディアやSNSなど総合的な支援が可能です。
媒体ごとに違うパートナーが入ることもなくスピーディな意思決定が可能です。
ご不明点や不安な点等ございましたらお気軽にお問い合わせください。 - サービス資料はこちら 詳しく見る
