2025.05.30
生成AIを活用しトピッククラスターの整理方法を考えてみた

メディアを運用するマーケティング担当者にとって、コンテンツのトピック整理は欠かせない施策の一つです。
しかし実際には、記事数が増えるにつれ、「どのテーマを深掘りすべきか」「どの情報が重複しているか」といった全体像の把握が難しくなります。結果として、精度高い施策実行に踏み切れない担当者も少なくないのではないでしょうか?
私自身、自社メディアを運用する中で、コンテンツが増え整理に手が回らなくなった経験があります。そんな中、生成AIの進化に注目し、解決策を求めてネット上で情報を調べましたが、自社の運用にフィットするノウハウは見つかりませんでした。
この記事では中堅のSEO担当者に向けて、生成AIを活用しながら効率的にトピッククラスターを整理し、施策に落とし込む方法を紹介します。専門用語はできる限り避け、あらゆるサイトにも応用しやすい構成で解説していきます。
目次
トピッククラスター整理の全体像

上記は、生成AIを活用したトピッククラスター整理の全体像を示したフローです。本記事では、このプロセスを大きく4つのステップに分けて解説します。
- 既存コンテンツの棚卸し
- 検索クエリの分析
- トピッククラスターの再設計
- 効果測定と改善サイクルの構築
それぞれのステップについて詳しく解説していきます。
まず既存コンテンツの棚卸しから始め、GASとSearch Console APIを活用して記事URLと検索クエリの一元管理を実施します。このデータをもとに、生成AIを活用して流入クエリの傾向を詳細に分析し、検索意図とコンテンツのミスマッチや重複コンテンツなどの問題点を効率的に特定していきます。
次のステップでは、分析データに基づいてトピッククラスターを再設計します。ピラーページとクラスターページの役割分担を明確化し、内部リンク構造も整理しながら、ユーザー導線とSEO効果の両立を図ることが可能になります。特に、ユーザーの検索意図に沿ったコンテンツ構成は、直帰率の改善にも大きく貢献します。
そして導入後は、アクセス解析データなどを用いた効果測定と継続的な改善サイクルの構築が重要です。今回は主要なKPIを紹介していますが、それらを適切に設定し、定期的なデータ検証を通じて戦略の調整を行うことで、長期的な流入改善効果を最大化できます。
現状の公開コンテンツ整理
トピッククラスターを構築する前に、まずは現在サイトにどんなコンテンツがあり、どのようなパフォーマンスを出しているかを把握する必要があります。この章では以下の3ステップで、既存コンテンツの棚卸しとパフォーマンス分析を行う具体的な方法を紹介します。
① サイトマップからの記事URL抽出
サイトに公開されている全記事のURL一覧を取得します。最も簡単な方法は、XMLサイトマップを利用して、全記事URLを抜き出す方法です。手作業でコピペするのは大変ですが、Google Apps Script (GAS) を使えば自動化が可能です。
以下はGoogleスプレッドシート+GASでサイトマップを出力し、URL一覧をシートに書き出すコード例です。スプレッドシート上で「ツール → スクリプトエディタ」を開き、サイトマップURLを運用メディアのものに書き換えたうえで、このコードを貼り付けて実行すると、「URL一覧」というシートにサイト内全記事のURLがリストアップされます。
さらに、各URLにアクセスしてページの<title>タグの内容を取得し、隣の列にページタイトルとして自動で書き出す処理も含まれています。記事一覧だけでなく、それぞれのページのタイトルも一覧で確認できるようになります。

コードコピー
function exportAllSitemapUrls() {
var sitemapUrl = ‘xxxx’; // 指定されたサイトマップURL
var ss = SpreadsheetApp.getActiveSpreadsheet();
var sheet = ss.getSheetByName(‘URL一覧’);
if (!sheet) {
sheet = ss.insertSheet(‘URL一覧’);
}
sheet.clearContents();
sheet.getRange(1, 1, 1, 3).setValues([[‘URL’, ‘ページタイトル’, ‘サイトマップタイプ’]]);
try {
// サイトマップを取得
var xmlText = UrlFetchApp.fetch(sitemapUrl).getContentText();
var document = XmlService.parse(xmlText);
var sitemapNs = XmlService.getNamespace(‘http://www.sitemaps.org/schemas/sitemap/0.9’);
var rootElement = document.getRootElement();
// サイトマップインデックスかどうかをチェック
var isIndex = rootElement.getName() === ‘sitemapindex’;
var rowCounter = 2; // ヘッダーの次の行から開始
if (isIndex) {
// サイトマップインデックスの場合、各サイトマップを処理
var sitemapElems = rootElement.getChildren(‘sitemap’, sitemapNs);
var sitemapUrls = [];
for (var i = 0; i < sitemapElems.length; i++) {
sitemapUrls.push(sitemapElems[i].getChild(‘loc’, sitemapNs).getText());
}
// 各サイトマップを処理
for (var j = 0; j < sitemapUrls.length; j++) {
var subSitemapUrl = sitemapUrls[j];
Logger.log(‘Processing sitemap: ‘ + subSitemapUrl);
try {
rowCounter = processSitemap(subSitemapUrl, sitemapNs, sheet, rowCounter);
} catch (e) {
Logger.log(‘Error processing sitemap ‘ + subSitemapUrl + ‘: ‘ + e.message);
}
}
} else {
// 通常のサイトマップの場合、URLを直接処理
Logger.log(‘Processing single sitemap: ‘ + sitemapUrl);
rowCounter = processSitemap(sitemapUrl, sitemapNs, sheet, rowCounter);
}
Logger.log(‘Completed. Total ‘ + (rowCounter–2) + ‘ URLs processed.’);
} catch (e) {
Logger.log(‘Error: ‘ + e.message);
sheet.getRange(2, 1).setValue(‘エラー: ‘ + e.message);
}
}
// サイトマップを処理する関数
function processSitemap(sitemapUrl, sitemapNs, sheet, startRow) {
var rowCounter = startRow;
var xmlText = UrlFetchApp.fetch(sitemapUrl).getContentText();
var document = XmlService.parse(xmlText);
var urlElems = document.getRootElement().getChildren(‘url’, sitemapNs);
// サイトマップのタイプを識別(ファイル名から)
var sitemapType = sitemapUrl.split(‘/’).pop();
// このサイトマップから各URLを処理
for (var k = 0; k < urlElems.length; k++) {
var elem = urlElems[k];
var pageUrl = elem.getChild(‘loc’, sitemapNs).getText();
// 進捗を表示するためにログ出力(100URLごと)
if (rowCounter % 100 === 0) {
Logger.log(‘Processed ‘ + rowCounter + ‘ URLs’);
}
// ページタイトルを取得
var title = ”;
try {
var html = UrlFetchApp.fetch(pageUrl, {
muteHttpExceptions: true,
followRedirects: true
}).getContentText();
var match = html.match(/<title>([\s\S]*?)<\/title>/i);
title = match ? match[1].trim() : ‘タイトル取得失敗’;
} catch (e) {
title = ‘Error: ‘ + e.message;
}
// データを書き込み
sheet.getRange(rowCounter, 1, 1, 3).setValues([[pageUrl, title, sitemapType]]);
rowCounter++;
// 処理制限に対応(1分あたりのAPIリクエスト数制限など)
if (rowCounter % 20 === 0) {
Utilities.sleep(1000); // 20URL処理ごとに1秒休止
}
}
return rowCounter;
}
② Search Consoleデータの活用(クエリ分析とGAS連携)
URLリストを取得したら、次に各ページの検索パフォーマンスを分析します。具体的には、Google検索からどのようなクエリ(検索キーワード)で流入があるのか、クリック数や表示回数、掲載順位はどうか、といったデータを把握します。これにはGoogle Search Consoleのデータを活用するのが良いです。
Search Console上では、特定のページごとに「このページはどんな検索クエリで表示・クリックされているか」を確認できます。しかし記事数が多い場合、APIを活用してデータを自動取得すると効率的です。GASはGoogleの各種APIと連携できるため、Search Console API経由でクエリデータを取得し、先ほどのURL一覧シートに統合することも可能です。
たとえば、直近3ヶ月の各ページごとの主要クエリ、表示回数、クリック数、平均掲載順位などを取得し、シートに出力してみましょう。それにより以下のような分析ができます。
- 各ページがどんな検索キーワードでアクセスを集めているか
- 想定していなかったクエリで流入していないか
- 検索順位が低く改善が必要なページはどれか
このようなデータは、Google Apps Script(GAS)を使って、Search Console APIから自動で取得できます。以下はAPIにリクエストする際の設定例(擬似コード)です。
コードコピー
const payload = {
startDate: “2025-02-01”,
endDate: “2025-04-30”,
dimensions: [“PAGE”, “QUERY”],
rowLimit: 5000
};
// ※実際にはOAuth認証やサイトURL(sc-domain:~)の指定等が必要
この設定を使うことで、期間内の「各ページ×クエリ」のデータを抽出できます。得られたデータはスプレッドシートでピボット集計すれば、「各URLの上位クエリ一覧」といった形で可視化できます。
このあとに紹介するGASコードを使えば、Search Consoleから取得したクエリデータと、前章で作成したサイトマップ由来のURL一覧とを1つのシートに統合することが可能です。
GCPの詳細な設定やAPI連携などの解説はここでは割愛しますが、コードが正しく動作をすれば、スプレッドシートのメニューに「Search Console分析」が追加されます。そこから順に操作を進めると、自動的に必要なデータが出力される仕組みです。
コードコピー
function onOpen() {
const ui = SpreadsheetApp.getUi();
ui.createMenu(‘Search Console分析’)
.addItem(‘APIテスト – サイト一覧取得’, ‘testSearchConsoleAPI’)
.addItem(‘URLの5位以内クエリを分析’, ‘getSearchConsoleData’)
.addToUi();
}
// 手動でメニューを追加する関数
function createMenu() {
const ui = SpreadsheetApp.getUi();
ui.createMenu(‘Search Console分析’)
.addItem(‘APIテスト – サイト一覧取得’, ‘testSearchConsoleAPI’)
.addItem(‘URLの5位以内クエリを分析’, ‘getSearchConsoleData’)
.addToUi();
ui.alert(‘メニューが追加されました’, ‘スプレッドシートの上部に「Search Console分析」メニューが追加されました。’, ui.ButtonSet.OK);
}
/**
* Search Console APIの接続をテストする関数
*/
function testSearchConsoleAPI() {
const ui = SpreadsheetApp.getUi();
try {
// Search Consoleのサイト一覧を取得
const sites = SearchConsole.Sites.list();
if (!sites || !sites.siteEntry || sites.siteEntry.length === 0) {
ui.alert(‘Search Consoleサイトが見つかりません’,
‘このGoogleアカウントにSearch Consoleのサイトへのアクセス権がありません。\n’ +
‘Search Consoleでサイトへのアクセス権を確認してください。’,
ui.ButtonSet.OK);
return;
}
// サイト一覧をメッセージとして表示
let message = ‘利用可能なサイト:\n\n’;
sites.siteEntry.forEach(site => {
message += ‘- ‘ + site.siteUrl + ‘\n’;
});
message += ‘\n接続テスト成功!Search Console APIにアクセスできています。’;
ui.alert(‘Search Console APIテスト成功’, message, ui.ButtonSet.OK);
} catch (error) {
Logger.log(‘エラー: ‘ + error);
ui.alert(‘Search Console API接続エラー’,
‘エラー: ‘ + error + ‘\n\n’ +
‘以下を確認してください:\n’ +
‘1. Google Cloud ConsoleでSearch Console APIが有効になっているか\n’ +
‘ → https://console.cloud.google.com/apis/library/searchconsole.googleapis.com\n’ +
‘2. このスクリプトでOAuthの認可が行われているか(初回実行時に許可が必要)\n’ +
‘3. スクリプトエディタの「サービス」から「Search Console API」を追加したか\n’ +
‘4. スクリプトエディタの「表示」→「ログ」で詳細なエラーログを確認する\n’,
ui.ButtonSet.OK);
}}
③ 流入クエリの質評価とコンテンツ改善(検索意図の不一致解消)
検索クエリのデータが揃ったら、流入しているキーワードの質を評価します。ここで言う「質」とは、そのクエリが流入を意図したユーザーとキーワードが合致しているか、ユーザーの検索意図に応えられているか、という視点です。
▼まず先に確認すべきこと
まずチェックしたいのが、検索意図の不一致(ミスマッチ)です。例えば「Aという記事」が、想定外のクエリ「B」でアクセスを集めていたとします。ユーザーは「B」を求めて来訪したのに、記事Aではその情報が十分提供されていないとしたら、ユーザーはすぐ離脱してしまうかもしれません。こうした検索意図のズレは高い直帰率や掲載順位の低下などにつながります。
ミスマッチ修正のアプローチ
- 該当ページのリライト:
流入クエリに対してコンテンツが不十分な場合、そのクエリの意図を満たす情報を追記・修正しましょう。例えばSearch Consoleで「~とは」「使い方」といったクエリが多いのに説明が薄ければ、その部分を補強します。 - 新規記事の作成:
あるページに明らかにテーマ違いのクエリが集まっている場合は、新しく専用の記事を立ち上げる方が良いです。例えば本来「初心者向けガイド」を想定した記事に「価格」や「比較」といった具体的な内容を検索しているクエリが来ている場合、後者向けに別の記事を用意し、適切に誘導することで両方の意図を満たせます。 - 検索意図に合わせたタイトル/ディスクリプション改善:
検索クエリに対してクリック率(CTR)が低い場合、検索結果上でユーザーの期待するタイトルになっていない可能性があります。タイトルに主要クエリを含めたり、魅力的なメタディスクリプションを設定したりして改善しましょう。
カニバリゼーションに注意
Search Consoleのデータから、同じクエリで複数ページにインプレッションが発生していればカニバリゼーションの可能性がありますその場合、記事の統合や構成見直しを検討し、どのページをその検索意図の「受け皿」にするか明確にします。
現状コンテンツの棚卸しとクエリ分析を経て、「どのトピック領域に強み・弱みがあるのか」「ユーザー需要に応え切れていない部分はどこか」が見えてきたと思います。次章では、これらを踏まえてトピッククラスターの設計と構築に進んでいきましょう。
SEO戦略の策定から実行まで、malnaがトータルサポート
「トピッククラスターを構築したいが、キーワード選定や構造化が追いつかない」 そんなお悩みはありませんか?
malnaでは、AIを活用した効率的な分析と、ユーザーニーズを深く捉えた高品質なコンテンツ制作をワンストップで支援しています。単なる順位向上ではなく、貴社の「本質的な事業成長」を支援するパートナーとして、最適なSEOプランをご提案します。
トピッククラスターの設計と構築
この章では現状分析をもとに、サイト内コンテンツを再編成するトピッククラスター戦略の立て方を解説します。トピッククラスターの基本とSEO上の意義を押さえた上で、効果的なトピック選定方法を紹介します。さらにコンテンツの抜けを洗い出す「ギャップ分析」や新規記事の計画についても触れていきます。
トピッククラスターの基本とSEO上の意義
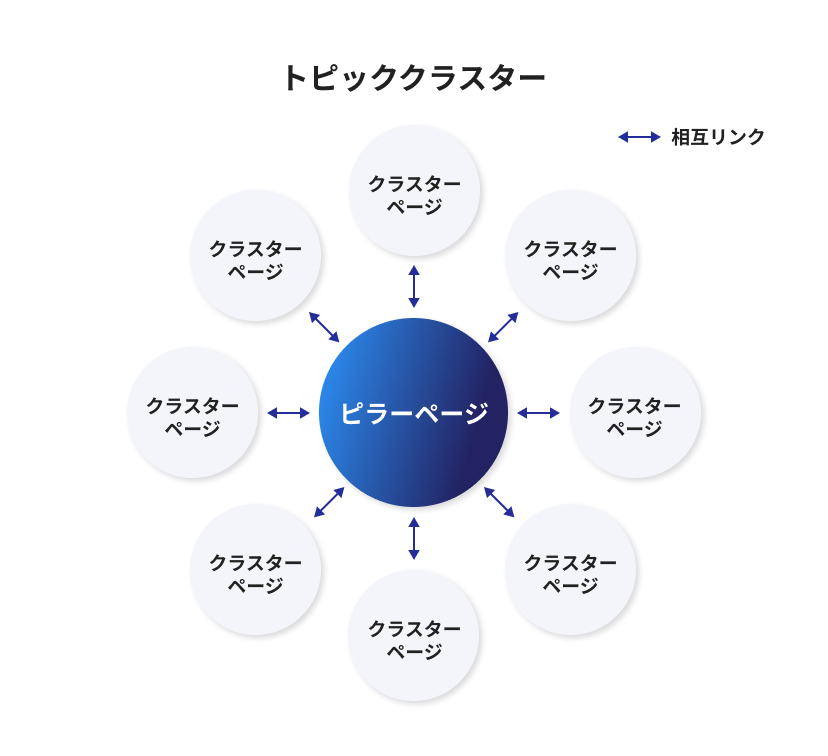
トピッククラスターとは、「ある主要トピックに関連する複数のサブトピック記事群を、内部リンクで体系的に繋げたコンテンツ構造」を指します。中心となる包括的な記事(ピラーページ)と、それを補完する詳細記事群(クラスターページ)を内部リンクで結ぶことで検索エンジンにとってもユーザーにとっても分かりやすい情報網を構築できます。
トピッククラスター戦略を採ることで得られるSEO上のメリットは数多くあります。
▼トピッククラスターがSEOにもたらす主な効果
- サイトの専門性・関連性が向上する
- 関連コンテンツをまとめて内部リンクすることで、そのトピックに関するサイト全体の関連性が高まります。Googleはコンテンツ間の関連性や網羅性を評価するため、クラスター化によりサイトのトピック権威性(トピカルオーソリティ)が向上します。
- クローラビリティが改善される
- 内部リンク構造が整理されることで、クローラーがサイト内を巡回しやすくなります。重要なページにリンクが集まるためクロールの優先度が上がり、新規コンテンツも発見されやすくインデックスも早くなります。
- ユーザー体験が向上する
- ユーザーは、興味あるテーマを深掘りしやすくなります。、「サイト内の回遊率アップ」「滞在時間の増加」「直帰率の低下」などにつながり、SEO評価にもプラスに働きます。
トピック選定手法
トピッククラスター戦略を実行するには、まず「どのトピックを中心に据えるか」を決める必要があります。ここでは手動による戦略的選定と、AIツールを活用した効率的な選定方法を組み合わせて紹介します。
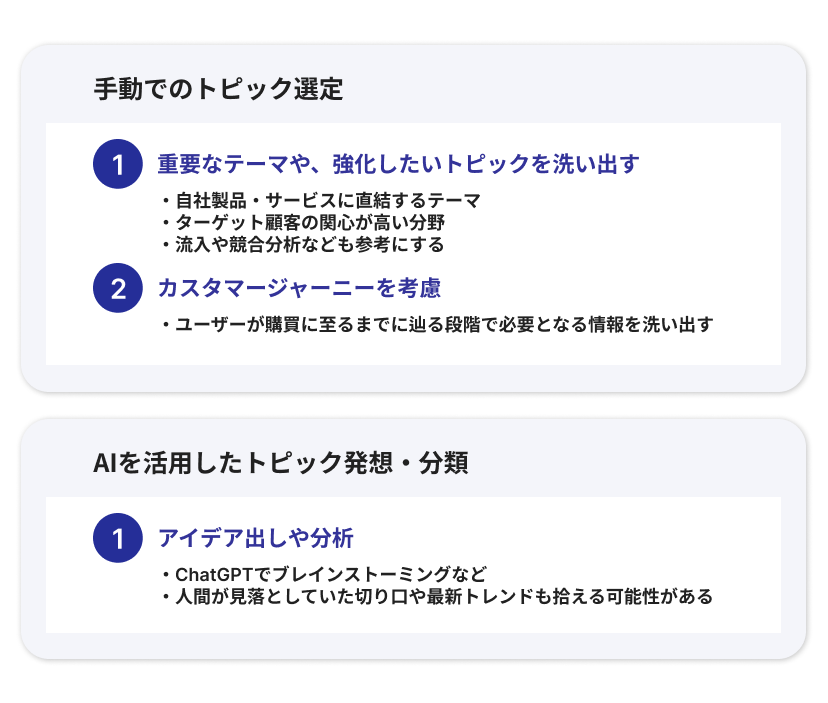
手動でのトピック選定
ビジネス視点から重要なテーマや、自社の専門領域で強化したいトピックを洗い出します。例えば、自社製品・サービスに直結するテーマや、ターゲット顧客の関心が高い情報分野です。現状コンテンツ分析で得た知見(流入が多い領域、競合に負けている領域など)も参考に、「この分野でサイトの権威性を高めたい」という主軸トピックを数個選びましょう。
またカスタマージャーニーを考慮することも有効です。ユーザーが購買に至るまでに辿る段階(認知→検討→決定など)それぞれで必要となる情報を洗い出すことで、網羅すべきトピックが見えてきます。
AIを活用したトピック発想・分類: 人間の視点だけでなく、AIにもアイデア出しや分析を手伝ってもらいましょう。人間が見落としていた切り口や最新トレンドも拾える可能性があります。
例えばChatGPTで以下のプロンプトを入力します。
ChatGPTへの具体的なプロンプト例
- トピッククラスター構造の提案を求めるプロンプト:
プロンプト例
当社はBtoBマーケティングツールを提供する企業で、主力製品はMAツール、CRM、リードナーチャリングツールです。各製品カテゴリーでピラーコンテンツとなるべき包括的トピックと、それぞれに紐づく5-8個のクラスターコンテンツトピックを提案してください。カスタマージャーニーの各段階(認知・検討・決定)にバランスよく対応する構成を意識してください。
- 既存コンテンツからクラスター構造を導き出すプロンプト:
プロンプト例
以下は当社ブログの人気記事タイトル一覧です:[記事タイトル一覧をペースト]
これらの記事を分析し、3-5個の主要トピッククラスターに分類してください。各クラスターごとに、1つのピラーコンテンツ候補と、それに紐づくクラスターコンテンツ候補を特定してください。また、各クラスターで不足していると思われるコンテンツテーマも提案してください。
- Search Consoleデータからのギャップ分析プロンプト:
プロンプト例
以下はSearch Consoleから抽出した、当社サイトで上位表示されているクエリとそれに対応するURLの一覧です:[データをペースト]
このデータを分析し、以下の観点で整理してください:
– どのようなトピッククラスターが自然に形成されているか
– 各クラスターの中で、どのページをピラーページとして強化すべきか
– 流入クエリから判断して、新たに作成すべきコンテンツはあるか
– 検索意図と現コンテンツのミスマッチが疑われるページはどれか
これらのプロンプトを活用することで、単なるアイデア出しだけでなく、データに基づいた構造的な分析と提案を得ることができます。重要なのは、自社の具体的なコンテキスト(業界、製品、ターゲット層など)をプロンプトに含めること、そして具体的な出力形式を指定することです。
トピック選定のポイント
最終的には「ビジネスにとって重要で、かつユーザーからの関心が大きい」テーマから優先的にクラスター化していくのがおすすめです。AIの提案も踏まえつつ、自社の強みや他社と差別化できるテーマを選びましょう。また既存記事が多い場合は、それらを活かしクラスター化すると効率的にコンテンツ戦略が立てられます。
コンテンツギャップの特定と新規で作成する記事を選定
トピックと大枠のクラスター構成が決まったら、既存コンテンツで不足している部分を洗い出し、新規記事の計画を立てます。これをコンテンツギャップ分析と呼びます。
コンテンツギャップを特定する方法
まず、選定した各トピックについて「ピラーページ+クラスターページ候補」の一覧を作成しましょう。該当する記事がない場合は「新規作成」とマークしておきます。ここでもAIが役立ちます。
例えば競合サイト上位のコンテンツを分析し、自社に無いトピックを抽出することが可能です。具体的には、競合サイトの主要カテゴリや人気記事タイトルをクローリングしてリスト化し、それらと自社コンテンツを比較します。
手作業では骨の折れる作業ですが、Pythonなどでクローリング+比較をしたり、ChatGPTに「競合Xのサイトマップから抽出したタイトル一覧」と「自社サイトのタイトル一覧」を渡して「自社に無いテーマはどれか?」と質問する、といった使い方もできます。
競合分析の視点
競合他社が構築しているトピッククラスターも参考になります。例えば、競合サイトで「〇〇 完全ガイド」といったピラーページがあり多くの内部リンクが張られているなら、その周辺にどんな子記事があるかを調べましょう。
SEOツール(AhrefsやSemrushの「コンテンツギャップ」機能など)を使えば、競合がランクインしているキーワードで自社が記事を持っていないものをリストアップできます。それらキーワードは新規記事のネタ候補になります。
加えて、Search Consoleで先述した意図不一致クエリが多かったものも、新規記事候補と言えます(既存記事ではカバーしきれない話題であるため)。
新規で作成する記事の選定
ギャップ分析から「作るべきコンテンツ」が見えてきたら、優先順位を付けて制作計画に落とし込みます。ここでもAIの活用が有効です。例えば、Notion AIやChatGPTに記事のアウトライン作成を依頼し、それを叩き台にライティングを進めると効率的です。
Keyword Insights等のツールを使えば、クラスター化したキーワード群ごとにAI生成のコンテンツブリーフ(見出し案や含めるべきトピックの提案)を出力できます。これをライターに渡すことで、抜け漏れの少ない記事を作成できるでしょう。
最後は人間の手で
ここで一つ注意したいのは、AIに頼りすぎて質を落とさないことです。近年、生成系AIの発達でコンテンツ量産は容易になりましたが、「関連するサブトピック記事をAIで大量生産し、片っ端から内部リンクで繋げればOK」というものではありません。
それでは内容が重複した記事が乱立し、どのページを主要なランディングページにすべきかコントロール不能になる恐れがあります。あくまでユーザーの検索意図と情報需要を満たすよう情報を整理・設計することが重要であり、AIはその支援役と位置付けましょう。
質の高いコンテンツを計画・制作し、それらを体系立てて結びつけることで初めて効果的なトピッククラスターが実現します。
以上のプロセスで、どのトピックにどのクラスターページを揃えるか(既存記事の流用 or 新規作成)が明確になったと思います。次章では、こうして構築したコンテンツ群をどう内部リンクで繋ぎ、最適化するかに焦点を当てます。
内部リンク構造の最適化
トピッククラスター戦略の効果を最大化するには、内部リンクの設計と最適化が欠かせません。ここでは、クラスターに基づく理想的な内部リンク設計と、AIを活用した内部リンク最適化する方法について解説します。
トピッククラスターに基づく内部リンク設計
トピッククラスターの構造に沿って、どのページからどのページへリンクを貼るかを設計します。基本となるのは以下の3点です。
- ピラーページ → クラスターページ
- 各ピラーページには、その主要トピックに関連するクラスターページへのリンクを網羅的に設置します。ユーザーがピラーページから詳細な関連情報へとすぐアクセスできるようにするためです。一般的にはピラーページ本文中や末尾に「関連記事一覧」や章リンクの形で配置します。
- クラスターページ → ピラーページ
- 全てのクラスターページから、対応するピラーページへのリンクを貼ります。こうすることで、ユーザーが細分化された記事から全体の包括ページに戻りやすくなり、サイト内ナビゲーションが向上します。またSEO的にも、関連ページ同士のリンクでクローラー巡回を促し、ピラーページにリンクジュース(評価の伝播)を集める効果があります。
- クラスターページ ↔ クラスターページ
- 必要に応じて、クラスターページ同士も相互にリンクします。特に内容が関連・補完し合う場合は、「〇〇については△△の記事も参考になります」といった形で双方向リンクすると良いでしょう。これにより、ユーザーが興味に応じて横断的に情報収集でき、クラスター内での回遊性が高まります。
アンカーテキスト最適化
内部リンクを貼る際のアンカーテキスト(リンク文言)は、リンク先ページの内容を端的に表すフレーズにします。SEO上はキーワードを含んだ自然な文言が理想です。例えば「内部リンクの重要性を理解するには、[内部リンク最適化のポイント]をご覧ください」というように、リンク先のタイトルや主題をそのままアンカーに盛り込むと関連性が明確になります。
決して「こちら」や「詳しくはコチラ→」といった汎用的すぎるテキストだけにならないよう注意しましょう(ユーザーにも検索エンジンにも内容が伝わらないため)。
ナビゲーションとサイト構造
トピッククラスターを導入する際、サイトのグローバルナビやカテゴリ構造も見直しましょう。可能であれば、主要クラスター=カテゴリ化し、グローバルナビからピラーページに直接アクセスできるようにすると効果的です。また、パンくずリストの設計もトピックベースに揃えることで、サイト構造の一貫性を高められます。
AIを活用したリンク最適化
内部リンク最適化の領域でも、AIの力を借りることで分析効率や精度を向上できます。以下、AIや関連ツールで可能なアプローチを紹介します。
AIによる関連ページ抽出
大量のコンテンツがある場合、「どの記事とどの記事をリンクすべきか」を手作業で考えるのは大変です。AIに文章を読ませ、内容の類似性やトピックの共通点を解析させれば、関連性の高いページ同士を推薦させることができます。
例えば、サイト内の各記事本文をベクトル(埋め込み)化し、そのコサイン類似度にもとづいて記事ペアを洗い出す、といったことが可能です。
難しく聞こえますが、近年はオープンソースの文章埋め込みモデルやクラウドのNLPサービスで比較的容易に実装できます。あるいはもっとシンプルに、ChatGPTに「記事Aの内容要約と記事Bの内容要約」を与えて「これらは相互にリンクすべき関連がありますか?」と尋ねる方法も考えられます。
AIは人間以上に膨大な組み合わせをチェックできるため、リンク漏れの発見や新たな内部リンク機会の発掘に役立ちます。
内部リンク構造の可視化
内部リンクの最適化状況を把握するには、サイト全体の内部リンク構造を可視化すると効果的です。専用のクローリングツールでサイトをクロールし、リンク構造をグラフ表示すれば、一目でクラスターの形が見えます。
例えばScreaming FrogやSitebulbでは、サイト内リンクのネットワークをクモの巣状のグラフやツリー構造で表示できます。ノード(ページ)の大きさを被リンク数に応じて変化させる機能もあり、重要ページに十分リンクが集まっているかの確認に便利です。下図はSitebulbによるクロールマップのイメージです(各点がページ、線が内部リンクを示す)
内部リンク自動化ツールの活用
近年では内部リンク貼り替えを自動化するツールも登場しています。その一つがInLinksです。InLinksはサイトをクロールして独自のナレッジグラフを構築し、ページ間の関連性をを検出します。その上で、サイト内におけるリンク機会を自動で見つけ出し、JavaScript経由で実際にリンクを挿入するところまで行えます。
例えば、「ページAとページBは共通して“SEO対策”というトピックを扱っているので相互にリンクしよう」といった具合に、サイト構造を理解した上での文脈リンクを実装してくれます。InLinksはアンカーテキストも単一のキーワードに固定せず、同義語やバリエーションを用いて自然な内部リンクを張る工夫もあります。
このようなAI搭載ツールを使えば、内部リンク最適化にかかる工数を大幅に削減できます。ただし自動化に任せきりにせず、提案内容を人間が吟味しつつ適用することが大切です。
内部リンク追加時のAI活用例
具体的な現場作業でもAIはサポートしてくれます。例えば既存記事をリライトしてリンクを差し込む際、ChatGPTに「この記事に関連する自社内の他記事を探してリンク候補を3つ挙げてください」とプロンプトを出すと、文章内容からリンクすべき記事を推察して提案してくれることがあります。
また、「記事Aの内容に沿って、記事Bへの内部リンクを自然に挿入する文章を作って」と頼めば、違和感のない挿入文を生成してくれるでしょう。こうしたティップスを活用しつつ、【人×AI】で着実にリンク網を張り巡らせていくのがおすすめです。
実装と効果測定
計画が整ったら、いよいよトピッククラスターの実装に移ります。一度にサイト全体を作り変えるのは大変ですので、段階的なアプローチで進めましょう。また、施策導入後は必ず効果測定を行い、PDCAサイクルで継続改善していきましょう。この章では、実装時の優先順位付けやリソース配分、効果測定の指標と改善の進め方について解説します。
実装アプローチ
まず、どのトピッククラスターから着手するかを決めましょう。第3章で整理した候補の中から、以下のようなビジネスインパクトが大きいものを優先するのがおすすめです。リソースが限られる場合は、1つのクラスターずつ順番に構築・最適化するのが現実的です。例えば今月は「SEO対策」クラスター、来月は「コンテンツマーケティング」クラスター、といった具合に計画を立てます。
カスタマージャーニーと子キーワード設計
各クラスター内の記事配置や内容は、カスタマージャーニー上のどの段階に属するかを意識して設計します。例えば「認知フェーズ」向けには初心者向けの包括コンテンツ(ピラーページ)や入門記事を配置し、「比較検討フェーズ」には具体的なHow-toやツール比較記事(クラスターページ)を、「意思決定フェーズ」には導入事例や料金ページへの誘導につながるコンテンツを配置するといった具合です。以下は簡単な対応表の例です。
| 購買プロセス段階 | ユーザーの主な関心 | 配置するコンテンツ例 | 内部リンク設計 |
|---|---|---|---|
| 認知・課題喚起 | 問題提起・基礎知識を得たい | 「○○とは」「○○の基礎」ピラーページ | 詳細記事(クラスターページ)へのリンクを散りばめる |
| 情報収集・比較検討 | 解決策の種類や詳細を知りたい | 「○○のやり方」「○○のツール比較」記事 | ピラーへ戻るリンク+関連クラスターページ同士のリンク |
| 意思決定・導入 | 導入事例・メリットを確認し判断したい | 「○○の成功事例」「サービス紹介ページ」 | サービスLPや問い合わフォームへのリンク |
上記のように、クラスター内でユーザーの心理ステージに応じた記事群を配置し、段階を進むごとに次のコンテンツへ内部リンクで誘導することで、自然なナビゲーションが生まれコンバージョンに繋げやすくなります。
既存記事のリライトと内部リンク追加
トピッククラスターの構築にあたっては、既存の記事のリライトと、内部リンクの最適化も欠かせません。ピラーページとなる記事は、関連クラスターページへのリンクを網羅するよう内容を拡充しましょう。
またクラスターページの冒頭や適切な文脈で「このテーマの全体像は●●の記事で解説しています」と追記するのも効果的です。そして、AIを使ったリライトも検討してください。例えば以下のように指示をします。
ChatGPTに記事全文と「この内容に関連する他の記事への内部リンクを3つ加えてリライトして」と指示すれば、リンク挿入済みのリライト案が得られるかもしれません。Notion AIを使って要約や簡潔化することも可能です。
レビューとテストを実施
クラスターを実装し終えたら、必ずレビューとテストを行いましょう。リンク切れがないか、リンクのアンカーテキストは適切か、ユーザー目線で読んで不自然な導線になっていないかを確認します。必要であれば社内の他メンバーや第三者に試用してもらい、フィードバックを集め改善します。
このようにクラスターごとにPDCAを回しながら順次展開していくことで、全体最適と品質維持を図ります。
効果測定と継続的改善
トピッククラスターを導入した後は、定量的な指標を追跡して効果測定を行います。また結果を踏まえて継続的に改善を重ねることが大切です。ここでは主要なKPI例とPDCAの回し方について説明します。
効果測定の主な指標
- 検索パフォーマンス指標
- Google Search Consoleで、クラスター導入後の関連ページの合計クリック数・表示回数の推移を確認します。特にピラーページの主要キーワードの平均順位や、クリック数の推移をチェックしてください。また、サイト全体のインデックス数やクロール数に変化があれば、クローラビリティ改善の効果が出ているという指標になります。
- ユーザー行動指標
- Googleアナリティクス等で、ページビュー数、直帰率、ページ滞在時間、サイト内回遊数などをモニタリングします。トピッククラスター導入で自然なリンク導線ができていれば、直帰率が下がり1訪問あたりのPV数が増加するはずです。
- コンバージョン指標
- お問い合わせ、資料請求、トライアル登録などのCV数・CV率も重要な指標です。ヒートマップ等でユーザーのクリック行動を分析し、内部リンク経由でサービスページに遷移しているか調べるのも有効です。
PDCAサイクルでの改善
PDCAサイクルによる改善例を紹介します。計測したデータをもとに、上手くいった点・課題点を洗い出し、次の施策に活かします。例えば、「クラスターページ群のPVは増えたが、ピラーページの伸びはいまひとつ」なら、ピラーへの誘導リンクが不足していないか再点検します。
また「滞在時間が短いページがある」なら、そのページの内容が浅かったり内部リンクの配置が悪い可能性があるため、追記やレイアウト変更を検討します。さらには、「想定外のキーワードで再び流入が増えてきた」場合、再度2.3節のような意図不一致解消サイクルを回します。このようにデータに基づいて仮説検証を繰り返すことで、トピッククラスターと内部リンク構造はより洗練されていきます。
▼定期的な見直しと環境変化への対応
検索エンジンのアルゴリズムやアップデートに対応するため、四半期ごとを目安にクラスター全体の見直しを行うのがおすすめです。主要キーワードの順位、競合の動き、検索ボリュームの変化などをチェックし、クラスターの再設計を検討しましょう。
AIツールを使えば大量の情報モニタリングも効率的です。「作って終わり」ではなく「育てるトピッククラスター」を意識していきましょう
まとめ
AIを活用したトピッククラスター構築と内部リンク最適化について紹介しました。
最後にお伝えしたいのは、トピッククラスターは一度構築して終わりではないということです。AIの力も活かしながら、常にアップデートされた情報設計を目指し、より強固なSEO戦略を築いていきましょう。
執筆者情報

- writer 野中 力斗 consultant
- デジタルマーケティング全般を担当。SEOの戦略設計と実行、コンテンツ制作、SalesforceやHubSpotなどのマーケティングオートメーションツールの運用、データ分析を通じた成果改善に注力。
2023年よりmalna株式会社に参画し、多角的なアプローチでクライアントの成長を支援。







関連記事タグをクリックでカテゴリページを開きます
-
2026.03.23
Claude CodeでSEO分析基盤をゼロから構築する全手順【実務者向け】
-
2025.05.30
【最新版】生成AI導入支援会社のおすすめ6選!選び方なども解説
-
2025.05.01
画像生成AIで素早く意図したものを生成する方法
-
2025.04.28
AI動画生成とは?仕組み・おすすめツール・活用事例を徹底解説
-
生成AIとは?仕組み・活用事例・リスク対策まで徹底解説【2025年版】
-
2025.04.05
なぜ生成AIが書いた文章に違和感が生まれるのか?







- malnaのマーケティングについて
-
弊社ではメディアやSNSなど総合的な支援が可能です。
媒体ごとに違うパートナーが入ることもなくスピーディな意思決定が可能です。
ご不明点や不安な点等ございましたらお気軽にお問い合わせください。 - サービス資料はこちら 詳しく見る
